Scaling Postgres in AWS and Google Cloud

So you’ve launched a new application in production, and your applications are performing snappily as you might expect. The cloud is infinitely scalable, right? A few months or a year down the road, you start noticing seemingly random slowdowns for Postgres queries that normally execute quickly. CPU and memory utilization look fine, so you start digging into the queries. The queries execute just fine in the staging environment, so you’re bewildered.
Scaling Postgres in an on-premise data center or in the cloud have their similarities and differences. One of the critical choke points in the world of Postgres is the management of open connections.
In this article, we’re going to cover some of the issues you might run into while scaling up the demand for your Postgres backend. More importantly, I’m going to detail some of the ways you can mitigate them.
Why Too Many Postgres Connections Are Problematic
In the past, prior to really dealing too much with Postgres, I – to a certain extent – understood that an RDBMS like MySQL had its limits for the number of practical open connections. Most of the time, the solution would be to increase max_connections and make sure that the system had enough memory to serve all of the per-connection buffers; not a trivial task, but somewhat easy to mitigate.
In my experiences working as an SRE at Malwarebytes, I learned how vastly different MySQL and Postgres deal with connections.
As you may know, in the standard MySQL configuration, one thread is created for each connection. In other words, the number of processes used is somewhat minimal.
In contrast, Postgres follows a process-per-user model. Because of this, creating new connections too rapidly or simply having too many connections open burdens the system more significantly.
The days of large monolithic application servers are sunsetting, and the new world of virtualized, containerized, autoscaling and load-balanced cloud applications is here. While the infrastructure’s instance counts were static, it was somewhat easy to manage connections, but with elastic infrastructure, careful considerations must be made to ensure that as the apps scale out, they don’t push Postgres to the point of no return.
A Relevant Story
While helping debug a production issue as a Senior SRE at Malwarebytes, I noticed that queries that ran quickly before were slowing down dramatically. The application didn’t yet have connection pooling implemented, so I looked into the number of connections opened to Postgres. We weren’t anywhere near our max connections, but everything was slowing down. CPU was getting fairly high at the time as well. The demand for connections kept growing as queries were retried and the client application that was making requests to our Postgres-backed API. This exacerbated the issue further.
The development team hot-fixed the connection pooling issue and I was able to effectively manage the number of connections allocated per application container.
This bought us some time until our applications needed even more connections. We were scaling up the number of clients rapidly.
There’s always a balance to be struck between allocating too many connections for an application and starving it. I scaled up the RDS master instance (no replicas at this point), which seemed to give us some breathing room, but it still kicked the can further down the road.
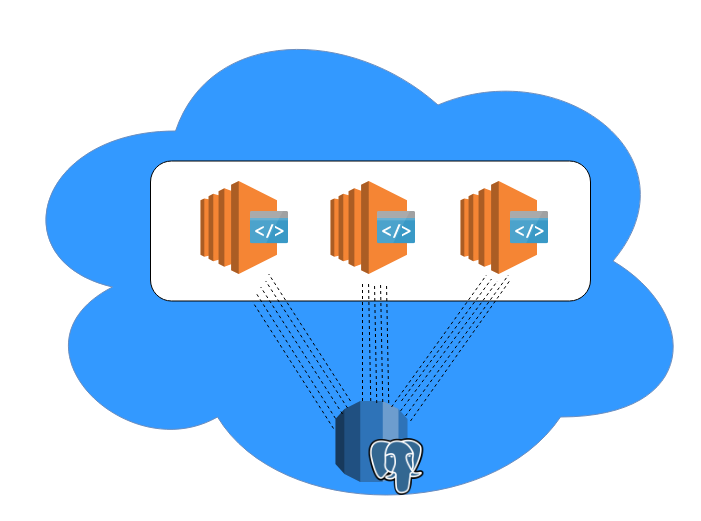
Managing Connections Effectively
So now that we understand the problem with opening too many connections, let’s highlight some mitigation techniques.
- Always implement application-side connection pooling in all of your apps:
- Part of managing elastic applications involves ensuring stability by making sure a single-application or containers don’t take down shared resources
- Enables you to control the upper and lower limits of your application’s connections to the database on a per-container/host basis
- Using an external connection pooling software (long-term solution):
- Enables you to control connections at a high level rather than just at the application
- Critical when scaling out your applications to tens or hundreds of containers/VMs
- Some external connection pooling softwares for Postgres:
In my experience, PgBouncer appears to perform extremely efficiently. While running load tests against one of the applications I manage (2000 rq/s) that’s backed by PgBouncer, the PgBouncer container only used 8 MB of memory and very minimal CPU.
One of the most critical things to consider if you’re looking towards an external connection pooling software is the transaction isolation method. This effectively dictates how well PgBouncer is able to reduce the total number of backend connections required. I tend to shoot for the ‘transaction’ pooling mode, as it will schedule inbound queries on a per-transaction basis towards the available backend connections. This makes it possible to serve 100 connections from your application across, say, 10 connections to the backend. Please see their documentation for a deeper dive on the available pooling modes.
Configuring PgBouncer
First, you’ll need to configure/bootstrap PgBouncer to:
- Recognize the database name it is to pool inbound connections for
- Automatically or manually generate the auth_file (see `here for a bash function`)
- A file that contains hashed authentication details that match with a user in the backend
- You can use the same username/password that the app would normally use to connect to the RDS/CloudSQL instance
- Control the characteristics of the connection pool opened to the backend (min, max, additional ’emergency’ connections)
- What port PgBouncer should listen on
Here’s an example config file that I used in my Dockerized version of PgBouncer:
[databases] $DATABASE_NAME = host=$DATABASE_HOST dbname=$DATABASE_NAME port=$DATABASE_PORT [pgbouncer] ignore_startup_parameters = client_min_messages # Listener config listen_port = 6432 listen_addr = * # Additional networking specs listen_backlog = 4096 # Authentication auth_type = md5 auth_file = userslist.txt # Stats / admin users for PGBouncer admin_users = $DATABASE_USERNAME stats_users = $STATS_COLLECTOR_USER # File management logfile = pgbouncer.log pidfile = pgbouncer.pid log_pooler_errors = 1 # Controls behavior of pooling mechanism pool_mode = $PGBOUNCER_POOL_MODE # Define the range of the pool default_pool_size = $PGBOUNCER_POOL_SIZE_MAX max_client_conn = $PGBOUNCER_MAX_CLIENT_CONNECTIONS max_user_connections = $PGBOUNCER_POOL_SIZE_MAX min_pool_size = $PGBOUNCER_POOL_SIZE_MIN max_db_connections = $PGBOUNCER_POOL_SIZE_MAX reserve_pool_size = $PGBOUNCER_POOL_ADDITIONAL_RESERVED # Timeouts server_idle_timeout = $PGBOUNCER_BACKEND_IDLE_TIMEOUT
PgBouncer Architecture/Scaling Strategy
Since high availability is usually the goal, you’ll want at least 2 instances of PgBouncer running. Try to keep the total number of connections to the backend below 100 if possible, provided that you’re using transaction pooling mode.
Remember that each instance of PgBouncer will be able to serve that number of requests, so if you had two instances of PgBouncer…
100 / 2 = 50 max connections per PgBouncer
4 instances of PgBouncer:
100 / 4 = 25 max connections per PgBouncer
Generating auth_file md5 Entries
The auth_file was one of the most confusing parts about PgBouncer for me personally. Effectively, you need to generate a hashed version of the password and username and store it in the userslist.txt file. This ensures that requests to PgBouncer are authenticated and enables you to connect to the backend database. The passwords between userlist.txt and the backend RDS/CloudSQL instance should match up.
Here’s a bash function that you can use to generate this ad-hoc or in an automated fashion:
generate_pg_hash_auth_token() {
local user=$1
local pass=$2
echo "Building PG user MD5 for user $user in auth file..."
pg_auth_md5=$(echo -n "$pass$user" | md5sum | awk '{ printf "md5%s", $1}')
echo "\"$user\" \"$pg_auth_md5\"" >> userslist.txt
}
Tying External Connection Pooling To RDS
So now that we’ve covered how PgBouncer works, let’s talk about what it would take to get it running.
Let’s say, for the sake of simplicity, that you want to use EC2 instances to host your PgBouncer (basically your new reverse proxy for database connections).
Get your instances rolled out and confirm that, from the PGBouncer instances, you’re able to connect to your RDS instance.
Create a DNS record for your PgBouncer instances (or to a TCP load balancer) and configure your applications to connect to that instead of the RDS instance’s DNS record. The RDS instance’s DNS record should already be in your PgBouncer’s database host configuration.
Of course, you’ll want to make sure all of your VPC and networking components allow access to the subnets and VPC security groups used by your RDS instance. This includes VPC routes, network ACLs, security groups and so on.
By now, if everything checks out, your applications should now be using PgBouncer to connect to your RDS instance.
Tying External Connection Pooling To Google CloudSQL
If you’re using CloudSQL in your Google environment, then you’re likely already familiar with the concept of using CloudSQL Proxy to access your CloudSQL instance. I don’t like to make my database servers publically available, so I chose to go the CloudSQL proxy route.
Quick Rundown On CloudSQL Proxy
For those of you that aren’t familiar, CloudSQL proxy is usually used as a sidecar to your application in order to facilitate accessing CloudSQL instances privately. It uses a service account key to authenticate with Google’s APIs in order to authorize queries.
In the case of Kubernetes, whereby the proxy is sidecar’d, your application will likely use ‘localhost’ as the database host, and whatever port that you have the CloudSQL proxy container running on (e.g. 5432).
The problem with using the proxy is that it doesn’t pool connections at a higher level. You still have a one-to-one relationship between the application container and CloudSQL proxy. As your app scales out, it can gobble up as many connections as it wants.
Integrating PgBouncer With CloudSQL Proxy
When I migrated our applications away from the CloudSQL proxy sidecar approach, I chose to create a separate Kubernetes service and deployment for each application’s PgBouncer component. Within each PgBouncer pod, I would sidecar CloudSQL proxy, instead of with the application. I’m going to give an example to hopefully make this clearer.
Let’s say I had two applications called “telem-api” and “user-api”.
In that case, I would have:
- Kubernetes Deployments:
- telem-api-pgbouncer
- Kubernetes Pod:
- 1x Pgbouncer Container, proxying connections to localhost @ CloudSQL proxy port
- 1x CloudSQL Proxy Container, pointed at my target CloudSQL instance
- user-api-pgbouncer
- Kubernetes Pod:
- 1x Pgbouncer Container, proxying connections to localhost @ CloudSQL proxy port
- 1x CloudSQL Proxy Container, pointed at my target CloudSQL instance
- Kubernetes Pod:
- Kubernetes Pod:
- telem-api-pgbouncer
- Kubernetes Services:
- telem-api-pgbouncer
- user-api-pgbouncer
Benefits Of Separate PgBouncer Instances Per Application
The idea here is to isolate the impact of any given application going haywire. If we had a shared database instance with multiple databases within it which are leveraged by multiple apps, we’d be in a safer position.
With this approach, we can also control how many database connections each application can open in said RDS/CloudSQL instance. Honestly, it also helped simplify the automation of dynamically building the PgBouncer configuration file too!
Other Performance Considerations
Whether you’re on RDS or CloudSQL, there are certainly other things that can degrade performance, which you might want to look into as well, such as:
- CPU resource limits:
- Make sure your DB instance has enough CPU to accomodate your workload
- If the performance issue just started happening recently, you may have some sequential (table) scans happening. Try tracking those down using:
EXPLAIN ${query}
- If the performance issue just started happening recently, you may have some sequential (table) scans happening. Try tracking those down using:
- Make sure your DB instance has enough CPU to accomodate your workload
- Disk throughput limits:
- Your RDS instance’s EBS volume may not be delivering the amount of performance your application’s workload requires; consider using Provisioned IOPS drives
- You may need to scale up the size of your CloudSQL instance or enable auto-provisioning for your drive to auto-scale your instance’s disk
- Database statistics not getting updated:
- Auto-vacuum/auto-analyze may not be running frequently enough or just might not be configured properly
- Look into enabling the extension pg_stat_statements to pull vacuum statistics and to find out which tables or indexes are most fragmented
These are just some of the things that could be hindering the performance of your PostgreSQL instances. I’ve found implementing connection pooling to have been one of the most profound contributors to improving the performance and scalability of our PostgreSQL-backed applications.
-- About the Author
About the Author
Marcus Bastian is a Senior Site Reliability Engineer that works with AWS and Google Cloud customers to implement, automate, and improve the performance of their applications.
Find his LinkedIn here.

DevOps Interview Questions
> Read more

5 DevOps Tools We Love
> Read more

PostgreSQL Monitoring with Datadog
> Read more

Tips for Getting AWS Solutions Architect Professional Certified
> Read more

Hiring DevOps Engineers: What You Need To Know
> Read more
Running an ECS Task on Each Cluster Machine
> Read more

Implementing AWS Parameter Store
> Read more
Monitoring Your Applications in AWS
> Read more

Accessing Secure Credentials in a Jenkins Pipeline
> Read more

When to Use AWS Lambda Functions VS Amazon ECS
> Read more

Configuring AWS Credentials with Access Keys, Secret Keys, and IAM Roles
> Read more

Downloading & Uploading Files in Amazon S3 using Python Boto3
> Read more